
LINKED LISTS Unit 5
Linked List Data Structure
A linked list is a linear data structure, in which the elements are not stored at contiguous memory locations. The elements in a linked list are linked using pointers as shown in the below image:
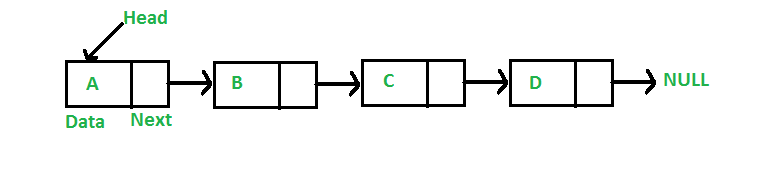
In simple words, a linked list consists of nodes where each node contains a data field and a reference(link) to the next node in the list.
similar types, but arrays have the following limitations.
1) The size of the arrays is fixed: So we must know the upper limit on the number of elements in advance. Also, generally, the allocated memory is equal to the upper limit irrespective of the usage.
2) Inserting a new element in an array of elements is expensive because the room has to be created for the new elements and to create room existing elements have to be shifted.
1) The size of the arrays is fixed: So we must know the upper limit on the number of elements in advance. Also, generally, the allocated memory is equal to the upper limit irrespective of the usage.
2) Inserting a new element in an array of elements is expensive because the room has to be created for the new elements and to create room existing elements have to be shifted.
For example, in a system, if we maintain a sorted list of IDs in an array id[].
id[] = [1000, 1010, 1050, 2000, 2040].
And if we want to insert a new ID 1005, then to maintain the sorted order, we have to move all the elements after 1000 (excluding 1000).
Deletion is also expensive with arrays until unless some special techniques are used. For example, to delete 1010 in id[], everything after 1010 has to be moved.
Deletion is also expensive with arrays until unless some special techniques are used. For example, to delete 1010 in id[], everything after 1010 has to be moved.
Advantages over arrays
1) Dynamic size
2) Ease of insertion/deletion
1) Dynamic size
2) Ease of insertion/deletion
Drawbacks:
1) Random access is not allowed. We have to access elements sequentially starting from the first node. So we cannot do binary search with linked lists efficiently with its default implementation. Read about it here.
2) Extra memory space for a pointer is required with each element of the list.
3) Not cache friendly. Since array elements are contiguous locations, there is locality of reference which is not there in case of linked lists.
1) Random access is not allowed. We have to access elements sequentially starting from the first node. So we cannot do binary search with linked lists efficiently with its default implementation. Read about it here.
2) Extra memory space for a pointer is required with each element of the list.
3) Not cache friendly. Since array elements are contiguous locations, there is locality of reference which is not there in case of linked lists.
Representation:
A linked list is represented by a pointer to the first node of the linked list. The first node is called the head. If the linked list is empty, then the value of the head is NULL.
Each node in a list consists of at least two parts:
1) data
2) Pointer (Or Reference) to the next node
In C, we can represent a node using structures. Below is an example of a linked list node with integer data.
C
Circular linked list is a linked list where all nodes are connected to form a circle. There is no NULL at the end. A circular linked list can be a singly circular linked list or doubly circular linked list.

Advantages of Circular Linked Lists:
1) Any node can be a starting point. We can traverse the whole list by starting from any point. We just need to stop when the first visited node is visited again.
1) Any node can be a starting point. We can traverse the whole list by starting from any point. We just need to stop when the first visited node is visited again.
2) Useful for implementation of queue. Unlike this implementation, we don’t need to maintain two pointers for front and rear if we use circular linked list. We can maintain a pointer to the last inserted node and front can always be obtained as next of last.
3) Circular lists are useful in applications to repeatedly go around the list. For example, when multiple applications are running on a PC, it is common for the operating system to put the running applications on a list and then to cycle through them, giving each of them a slice of time to execute, and then making them wait while the CPU is given to another application. It is convenient for the operating system to use a circular list so that when it reaches the end of the list it can cycle around to the front of the list.
4) Circular Doubly Linked Lists are used for implementation of advanced data structures like Fibonacci Heap.

Application of Circular Linked List
- The real life application where the circular linked list is used is our Personal Computers, where multiple applications are running. All the running applications are kept in a circular linked list and the OS gives a fixed time slot to all for running. The Operating System keeps on iterating over the linked list until all the applications are completed.
- Another example can be Multiplayer games. All the Players are kept in a Circular Linked List and the pointer keeps on moving forward as a player's chance ends.
- Circular Linked List can also be used to create Circular Queue. In a Queue we have to keep two pointers, FRONT and REAR in memory all the time, where as in Circular Linked List, only one pointer is required.
Implementing Circular Linked List
Implementing a circular linked list is very easy and almost similar to linear linked list implementation, with the only difference being that, in circular linked list the last Node will have it's next point to the Head of the List. In Linear linked list the last Node simply holds NULL in it's next pointer.
So this will be oue Node class, as we have already studied in the lesson, it will be used to form the List.
class Node {
public:
int data;
//pointer to the next node
node* next;
node() {
data = 0;
next = NULL;
}
node(int x) {
data = x;
next = NULL;
}
}
Circular Linked List
Circular Linked List class will be almost same as the Linked List class that we studied in the previous lesson, with a few difference in the implementation of class methods.
class CircularLinkedList {
public:
node *head;
//declaring the functions
//function to add Node at front
int addAtFront(node *n);
//function to check whether Linked list is empty
int isEmpty();
//function to add Node at the End of list
int addAtEnd(node *n);
//function to search a value
node* search(int k);
//function to delete any Node
node* deleteNode(int x);
CircularLinkedList() {
head = NULL;
}
}
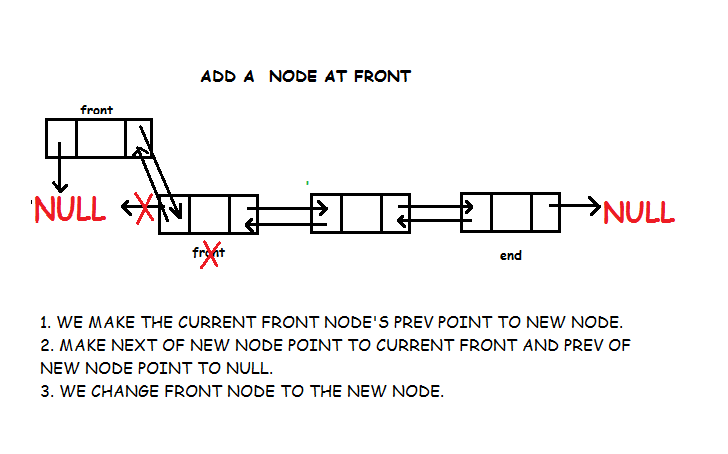
Insertion at the Beginning
Steps to insert a Node at beginning :
- The first Node is the Head for any Linked List.
- When a new Linked List is instantiated, it just has the Head, which is Null.
- Else, the Head holds the pointer to the fisrt Node of the List.
- When we want to add any Node at the front, we must make the head point to it.
- And the Next pointer of the newly added Node, must point to the previous Head, whether it be NULL(in case of new List) or the pointer to the first Node of the List.
- The previous Head Node is now the second Node of Linked List, because the new Node is added at the front.
int CircularLinkedList :: addAtFront(node *n) {
int i = 0;
/* If the list is empty */
if(head == NULL) {
n->next = head;
//making the new Node as Head
head = n;
i++;
}
else {
n->next = head;
//get the Last Node and make its next point to new Node
Node* last = getLastNode();
last->next = n;
//also make the head point to the new first Node
head = n;
i++;
}
//returning the position where Node is added
return i;
}
Insertion at the End
Steps to insert a Node at the end :
- If the Linked List is empty then we simply, add the new Node as the Head of the Linked List.
- If the Linked List is not empty then we find the last node, and make it' next to the new Node, and make the next of the Newly added Node point to the Head of the List.
int CircularLinkedList :: addAtEnd(node *n) {
//If list is empty
if(head == NULL) {
//making the new Node as Head
head = n;
//making the next pointer of the new Node as Null
n->next = NULL;
}
else {
//getting the last node
node *last = getLastNode();
last->next = n;
//making the next pointer of new node point to head
n->next = head;
}
}
Searching for an Element in the List
In searhing we do not have to do much, we just need to traverse like we did while getting the last node, in this case we will also compare the data of the Node. If we get the Node with the same data, we will return it, otherwise we will make our pointer point the next Node, and so on.
node* CircularLinkedList :: search(int x) {
node *ptr = head;
while(ptr != NULL && ptr->data != x) {
//until we reach the end or we find a Node with data x, we keep moving
ptr = ptr->next;
}
return ptr;
}
Deleting a Node from the List
Deleting a node can be done in many ways, like we first search the Node with data which we want to delete and then we delete it. In our approach, we will define a method which will take the data to be deleted as argument, will use the search method to locate it and will then remove the Node from the List.
To remove any Node from the list, we need to do the following :
- If the Node to be deleted is the first node, then simply set the Next pointer of the Head to point to the next element from the Node to be deleted. And update the next pointer of the Last Node as well.
- If the Node is in the middle somewhere, then find the Node before it, and make the Node before it point to the Node next to it.
- If the Node is at the end, then remove it and make the new last node point to the head.
node* CircularLinkedList :: deleteNode(int x) {
//searching the Node with data x
node *n = search(x);
node *ptr = head;
if(ptr == NULL) {
cout << "List is empty";
return NULL;
}
else if(ptr == n) {
ptr->next = n->next;
return n;
}
else {
while(ptr->next != n) {
ptr = ptr->next;
}
ptr->next = n->next;
return n;
}
}Doubly Linked List
A Doubly Linked List (DLL) contains an extra pointer, typically called previous pointer, together with next pointer and data which are there in singly linked list.
Following is representation of a DLL node in C language.
- C
Following are advantages/disadvantages of doubly linked list over singly linked list.
Advantages over singly linked list
1) A DLL can be traversed in both forward and backward direction.
2) The delete operation in DLL is more efficient if pointer to the node to be deleted is given.
3) We can quickly insert a new node before a given node.
In singly linked list, to delete a node, pointer to the previous node is needed. To get this previous node, sometimes the list is traversed. In DLL, we can get the previous node using previous pointer.
1) A DLL can be traversed in both forward and backward direction.
2) The delete operation in DLL is more efficient if pointer to the node to be deleted is given.
3) We can quickly insert a new node before a given node.
In singly linked list, to delete a node, pointer to the previous node is needed. To get this previous node, sometimes the list is traversed. In DLL, we can get the previous node using previous pointer.
Disadvantages over singly linked list
1) Every node of DLL Require extra space for an previous pointer. It is possible to implement DLL with single pointer though (See this and this).
2) All operations require an extra pointer previous to be maintained. For example, in insertion, we need to modify previous pointers together with next pointers. For example in following functions for insertions at different positions, we need 1 or 2 extra steps to set previous pointer.
1) Every node of DLL Require extra space for an previous pointer. It is possible to implement DLL with single pointer though (See this and this).
2) All operations require an extra pointer previous to be maintained. For example, in insertion, we need to modify previous pointers together with next pointers. For example in following functions for insertions at different positions, we need 1 or 2 extra steps to set previous pointer.
Insertion
A node can be added in four ways
1) At the front of the DLL
2) After a given node.
3) At the end of the DLL
4) Before a given node.
A node can be added in four ways
1) At the front of the DLL
2) After a given node.
3) At the end of the DLL
4) Before a given node.
Implementation of Doubly Linked List
First we define the node.
struct node
{
int data; // Data
node *prev; // A reference to the previous node
node *next; // A reference to the next node
};
Now we define our class Doubly Linked List. It has the following methods:
- add_front: Adds a new node in the beginning of list
- add_after: Adds a new node after another node
- add_before: Adds a new node before another node
- add_end: Adds a new node in the end of list
- delete: Removes the node
- forward_traverse: Traverse the list in forward direction
- backward_traverse: Traverse the list in backward direction
class Doubly_Linked_List
{
node *front; // points to first node of list
node *end; // points to first las of list
public:
Doubly_Linked_List()
{
front = NULL;
end = NULL;
}
void add_front(int );
void add_after(node* , int );
void add_before(node* , int );
void add_end(int );
void delete_node(node*);
void forward_traverse();
void backward_traverse();
};Insert Data in the beginning
- The prev pointer of first node will always be NULL and next will point to front.
- If the node is inserted is the first node of the list then we make front and end point to this node.
- Else we only make front point to this node.
void Doubly_Linked_List :: add_front(int d)
{
// Creating new node
node *temp;
temp = new node();
temp->data = d;
temp->prev = NULL;
temp->next = front;
// List is empty
if(front == NULL)
end = temp;
else
front->prev = temp;
front = temp;
}Insert Data before a Node
Let’s say we are inserting node X before Y. Then X’s next pointer will point to Y and X’s prev pointer will point the node Y’s prev pointer is pointing. And Y’s prev pointer will now point to X. We need to make sure that if Y is the first node of list then after adding X we make front point to X.
void Doubly_Linked_List :: add_before(node *n, int d)
{
node *temp;
temp = new node();
temp->data = d;
temp->next = n;
temp->prev = n->prev;
n->prev = temp;
//if node is to be inserted before first node
if(n->prev == NULL)
front = temp;
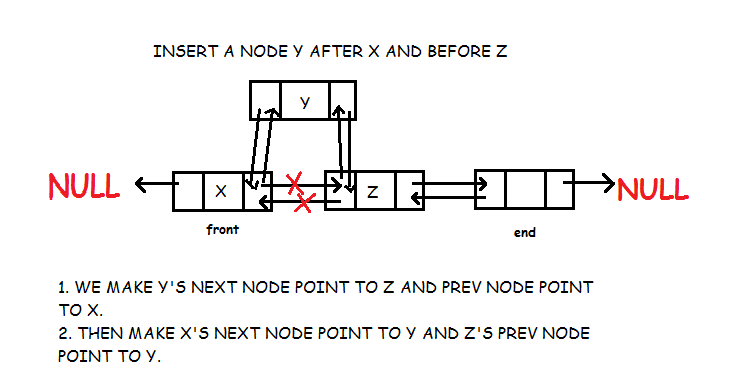
} Insert Data after a Node
Let’s say we are inserting node Y after X. Then Y’s prev pointer will point to X and Y’s next pointer will point the node X’s next pointer is pointing. And X’s next pointer will now point to Y. We need to make sure that if X is the last node of list then after adding Y we make end point to Y.
void Doubly_Linked_List :: add_after(node *n, int d)
{
node *temp;
temp = new node();
temp->data = d;
temp->prev = n;
temp->next = n->next;
n->next = temp;
//if node is to be inserted after last node
if(n->next == NULL)
end = temp;
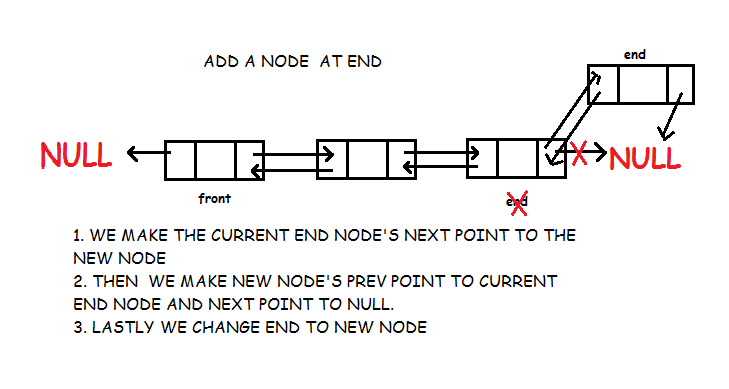
}Insert Data in the end
- The next pointer of last node will always be NULL and prev will point to end.
- If the node is inserted is the first node of the list then we make front and end point to this node.
- Else we only make end point to this node.
void Doubly_Linked_List :: add_end(int d)
{
// create new node
node *temp;
temp = new node();
temp->data = d;
temp->prev = end;
temp->next = NULL;
// if list is empty
if(end == NULL)
front = temp;
else
end->next = temp;
end = temp;
}Remove a Node
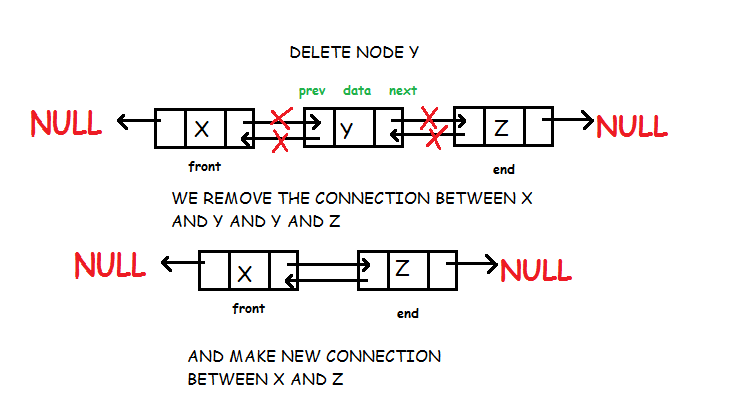
Removal of a node is quite easy in Doubly linked list but requires special handling if the node to be deleted is first or last element of the list. Unlike singly linked list where we require the previous node, here only the node to be deleted is needed. We simply make the next of the previous node point to next of current node (node to be deleted) and prev of next node point to prev of current node. Look code for more details.
void Doubly_Linked_List :: delete_node(node *n)
{
// if node to be deleted is first node of list
if(n->prev == NULL)
{
front = n->next; //the next node will be front of list
front->prev = NULL;
}
// if node to be deleted is last node of list
else if(n->next == NULL)
{
end = n->prev; // the previous node will be last of list
end->next = NULL;
}
else
{
//previous node's next will point to current node's next
n->prev->next = n->next;
//next node's prev will point to current node's prev
n->next->prev = n->prev;
}
//delete node
delete(n);
}Forward Traversal
Start with the front node and visit all the nodes untill the node becomes NULL.
void Doubly_Linked_List :: forward_traverse()
{
node *trav;
trav = front;
while(trav != NULL)
{
cout<<trav->data<<endl;
trav = trav->next;
}
}Backward Traversal
Start with the end node and visit all the nodes until the node becomes NULL.
void Doubly_Linked_List :: backward_traverse()
{
node *trav;
trav = end;
while(trav != NULL)
{
cout<<trav->data<<endl;
trav = trav->prev;
}
}
Difference between Stack and Queue Data Structures
| STACKS | QUEUES |
|---|---|
| Stacks are based on the LIFO principle, i.e., the element inserted at the last, is the first element to come out of the list. | Queues are based on the FIFO principle, i.e., the element inserted at the first, is the first element to come out of the list. |
| Insertion and deletion in stacks takes place only from one end of the list called the top. | Insertion and deletion in queues takes place from the opposite ends of the list. The insertion takes place at the rear of the list and the deletion takes place from the front of the list. |
| Insert operation is called push operation. | Insert operation is called enqueue operation. |
| Delete operation is called pop operation. | Delete operation is called dequeue operation. |
| In stacks we maintain only one pointer to access the list, called the top, which always points to the last element present in the list. | In queues we maintain two pointers to access the list. The front pointer always points to the first element inserted in the list and is still present, and the rear pointer always points to the last inserted element. |
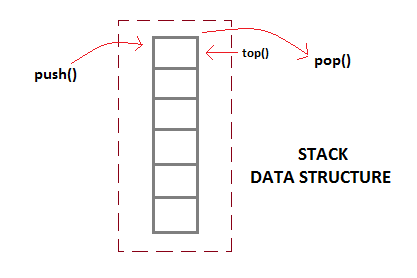
Stack using Linked List
Stack as we know is a Last In First Out(LIFO) data structure. It has the following operations :
- push: push an element into the stack
- pop: remove the last element added
- top: returns the element at top of stack
Implementation of Stack using Linked List
Stacks can be easily implemented using a linked list. Stack is a data structure to which a data can be added using the
push() method and data can be removed from it using the pop() method. With Linked list, the push operation can be replaced by the addAtFront() method of linked list and pop operation can be replaced by a function which deletes the front node of the linked list.
In this way our Linked list will virtually become a Stack with
push() and pop() methods.
First we create a class node. This is our Linked list node class which will have data in it and a node pointer to store the address of the next node element.
class node
{
int data;
node *next;
};
Then we define our stack class,
class Stack
{
node *front; // points to the head of list
public:
Stack()
{
front = NULL;
}
// push method to add data element
void push(int);
// pop method to remove data element
void pop();
// top method to return top data element
int top();
};Inserting Data in Stack (Linked List)
In order to insert an element into the stack, we will create a node and place it in front of the list.
void Stack :: push(int d)
{
// creating a new node
node *temp;
temp = new node();
// setting data to it
temp->data = d;
// add the node in front of list
if(front == NULL)
{
temp->next = NULL;
}
else
{
temp->next = front;
}
front = temp;
}
Now whenever we will call the
push() function a new node will get added to our list in the front, which is exactly how a stack behaves.Removing Element from Stack (Linked List)
In order to do this, we will simply delete the first node, and make the second node, the head of the list.
void Stack :: pop()
{
// if empty
if(front == NULL)
cout << "UNDERFLOW\n";
// delete the first element
else
{
node *temp = front;
front = front->next;
delete(temp);
}
}Return Top of Stack (Linked List)
In this, we simply return the data stored in the head of the list.
int Stack :: top()
{
return front->data;
}Conclusion
When we say "implementing Stack using Linked List", we mean how we can make a Linked List behave like a Stack, after all they are all logical entities. So for any data structure to act as a Stack, it should have
push() method to add data on top and pop() method to remove data from top. Which is exactly what we did and hence accomplished to make a Linked List behave as a Stack.
No comments:
Post a Comment